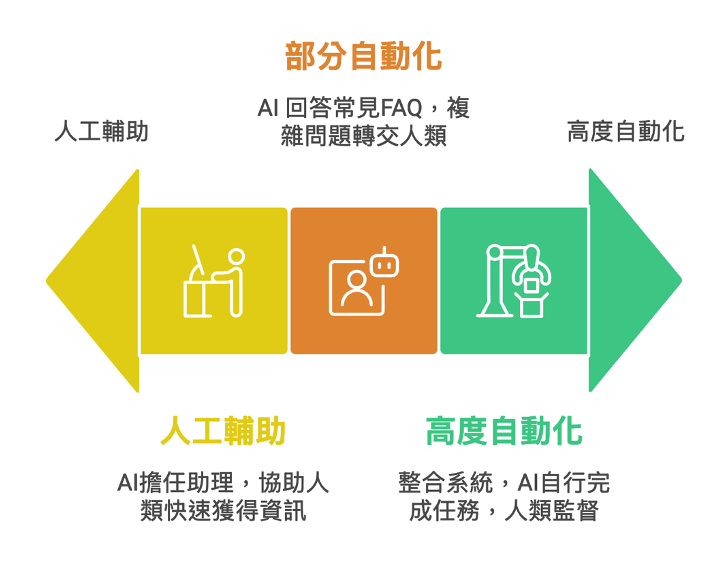
美國維吉尼亞大學助理教授莎拉‧萊博維茨(Sarah Lebovitz)在2023年《麻省理工學院史隆管理評論》(MIT Sloan Management Review)中,發表了一篇文章〈評估人工智慧工具時要問的第一個問題〉(The No. 1 Question to Ask When Evaluating AI Tools)。裡面提到人工智慧(AI)工具中基準真相(Ground Truth)的重要性。
在快速發展且競爭激烈的AI領域中,開發者通常聲稱其AI工具能夠以高精準度做出預測,這已成為向潛在客戶推廣其價值的重要依據。然而,對於非AI專家而言,評估這些工具可能讓人感到困擾,企業領導者可能更傾向於仰賴銷售資料中所公佈的績效指標。
這種作法往往會導致推行AI的結果不盡人意。因此,該研究深入探討了管理者如何深入研究AI工具,以更全面地評估AI工具是否有助於提升企業的決策能力。該研究指出,確定AI工具品質的有效方法,在於理解並檢驗其基準真相(Ground Truth)。
到底AI工具的基準真相是什麼?
根據該研究的界定,在AI領域中,這些基準真相指的是訓練資料集中的數據。這些數據用來指導演算法如何預測輸出。
該研究舉例,訓練一個模型以辨識最佳的職位候選人,這背後需要一個包含候選人特徵的訓練資料集,如教育程度、工作經驗等。在這資料集中,每個特徵都與「理想候選人」或「不理想候選人」的分類相關聯。又例如,用於預測熱帶風暴影響的AI,可能使用保險理賠和政府急難支出等數據,作為將天氣事件標記為「高度破壞性」或「非高度破壞性」的基準真相。
因此,基準真相是建立在客觀、經驗驗證的已知真實資訊上的。而AI工具的品質和對組織的價值,主要受制於用於訓練和驗證的基準真相的品質。
然而,在使用訓練資料集時,可能存在風險,特別是當資料集缺乏代表性或包含了具有偏見的特徵時。例如,判斷是否為「理想候選人」時,教育程度、工作經驗等條件是否具有代表性。
該研究以醫療領域為例,指出AI開發人員在選擇使用哪些基準真相,來訓練和驗證癌症診斷模型時會面臨重大權衡。
首先,他們可能選擇使用活檢結果作為基準真相,提供是否檢測到癌症的外部驗證結果。然而,由於大多數患者從未接受過活檢,要為訓練資料集中的所有患者獲取這些結果,需要巨大的投資以及與患者的合作。
或者,開發人員可以利用臨床醫生記錄的診斷,這些數據可從歷史電子健康記錄中獲得。亦或是開發人員還能招募專家小組,使用他們的平均或多數意見作為基準真相,對訓練資料集中的病例樣本進行診斷。儘管建立這樣的資料集可能成本高昂且耗時,但在醫療AI社群中卻是一種常見的方法。
總之,AI開發人員在建立基準真相時,需要權衡相對的成本和收益,這個決策對工具的整體品質和潛在價值有著重大的影響。
該研究建議管理者應與AI供應商和內部開發團隊深入接觸,並就他們的基準真相選擇、這些選擇背後的邏輯,以及他們考慮的任何權衡進行公開對話。這樣的開放對話有助於建立信任,確保相關利害關係者能夠理解AI工具的基準真相,並對其合法性和可靠性感到安心。
羅凱揚(台科大企管博士)、黃揚博(海豚AI學院創辦人、突圍智創執行長、臺大商研博士班)
資料來源:Lebovitz, S., Lifshitz-Assaf, H., & Levina, N. (2023). The No. 1 Question to Ask When Evaluating AI Tools. MIT Sloan Management Review, 64(3), 27-30.